NOTE: This post is based off a talk I recently (2018/05) gave at Pycon9 in Firenze.
I have been working as a Data Scientist for a while now, and I can safely say that I got to know a few things. The main thing I learned is that, when you can abstract a problem you are working on and derive generic tools to solve similar problem out of it, you should DEFINITELY go ahead and do it. Even if you won’t be able to develop your solution for your current project, it will almost certainly be useful for something else in the future (or for someone else).
This is what drove me to spend quite some time implementing a library to help during a project I was working on a few months ago.
The problem
Clearly, I can’t say too much about the project, the data, the issue, or the specific solution we ended up using. I’ll have to get creative and keep everything extremely vague and mysterious… Sorry…
Essentially: we had a system used by internal and external users. Users would go through a sequence of steps (we’ll call these ‘states’ or ‘nodes’) in sequence; each step in the sequence was associated with an outcome. Depending on how each session ended, we had sessions that were problematic and sessions that were not.

Our project was the analysis of the sequences or sessions in order to determine what drives good vs. bad final outcomes.
I know it sound complex when described like this, but it actually was pretty hard to get…
The side project
While working on that project, we used Markov Chains to describe some sequences and to determine which nodes where responsible for bad user outcomes. The problem was: we were using 

That’s when I decided to start working on a general library that could implement Markov Chains of any order.
But first things first…
What is a Markov Chain
A Markov chain is collection of random variables 

That is, the probability of being in a certain state depends ONLY on the previous state.
This sounds like a big approximation, that would have nothing to do with real life… and yet it works quite well and it has a lot of practical applications.
Anyway, given this definition, we can construct a simple example to show how exactly a MC works:
Suppose we have a sequence:

Based on these numbers we can say that:
- If the current state is 1, there is a 100% probability of moving to state 2;
- if the current state is 2, there is 66% probability of evolving to state 1 and 33% of evolving to state 3;
- if the current state is 3, there is a 100% probability of evolving to state 1.
And this is, in essence, all there is to it. We can represent this evolution using different techniques: we can use a matrix to represent probabilities of evolving form one state to another (useful for calculations), or we can use a graph to visualise all the paths.


The two figures and the show the exact same representation of the numeric sequence.
How is this useful?
Well…
Now we have a representation of probabilities of evolution and an initial state. We ca derive the (probabilistic) future state.
The next state in the sequence can be represented as:

where 
This can be extended to an arbitrary number of steps by taking the matrix power of the transition matrix:

Another extension to this definition is to include subsequences of states in the transition matrix, so that you’re not only considering the current state when predicting the next, but also the previous (or more).
A bit of code
NOTE: the code shown below is not complete and lacks a lot of necessary features (error handling, docstrings, ...) for better clarity. You should NOT run it as is...
Class initialisation:
class MarkovChain(object):
def __init__(self, n_states, order=1):
self.number_of_states = n_states
self.order = order
self.possible_states = {
j: i for i, j in
enumerate(
itertools.product(range(n_states),
repeat=order)
)
(len(self.possible_states), len(self.possible_states))
), dtype=np.float64)
Essentially, we generate the number of all possible states (which depends on the order of the MC), and we initialise an emprt `dok` matrix from `scipy.sparse`.
We use a `dok` matrix because it’s fast to initialise and update, but it’snot the most efficient structure for computation, as we’ll see below.
Now that we have the initialiser for the parameters and the transition matrix, we need a method that updates it when a state change is detected in a sequence:
def update_transition_matrix(self, states_sequence): visited_states = [ states_sequence[i: i + self.order] for i in range(len(states_sequence) - self.order + 1) ] for state_index, i in enumerate(visited_states): self.transition_matrix[ self.possible_states[tuple(i)], self.possible_states[tuple(visited_states[ state_index + self.order ])] ] += 1 def normalise_transitions(self): self.transition_matrix = preprocessing.normalize( self.transition_matrix, norm="l1" )
This snippet of code takes a sequence of states as argument and constructs the sequence of states that needs to be updated. Then it adds `1` to the transition matrix at the appropriate position. This is basically a count of all the times the sequence goes from state `i` to state `j`.
Now, since the transition matrix holds probabilities, we need to make sure all the rows are normalised. That is the purpose of `normalise_transitions`.
We have all the building blocks to start making predictions now!
def predict_state(self, current_state, num_steps=1): _next_state = sparse.csr_matrix(current_state).dot( np.power(self.transition_matrix, num_steps) ) return _next_state
And there we go. We have all the pieces in place to start using this.
A quick demo
I built a small interactive tool to help me use this library (not included in the repo :p ).
The library requires the sequences to be numeric. Each number corresponding to a unique state. To achieve best performance, I relabeled the data so that it spanned from 0 to number of states.
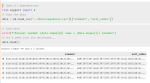


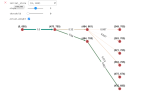
Having fit the model with the sequences, I built a small tool with NetworkX, Jupyter widgets and some good old Python magic to let me inspect the future of a generic state.
In this case I used a 
And that’s all folks!
If you liked it or if you think it might be useful to you, the code is open source (link below).
